클러스터 모드로 spark-submit 명령을 수행했을 때 spark application이 어떤 순서로 작동하는지 알아본다.
클라이언트의 요청

첫 단계는 스파크 애플리케이션(컴파인된 JAR파일이나 라이브러리 파일)을 제출하는 것. 스파크 어플리케이션을 제출하면 로컬에서 코드가 실행되어 클러스터 드라이버 노드에 요청한다. 이 과정에서 스파크 드라이버 프로세스의 자원을 함께 요구한다. 클러스터 매니저가 이 요청을 받아들이면 클러스터 워커 노드 중 한 곳에서 스파크 드라이버 프로세스를 실행한다. 스파크 잡을 제출한 클라이언트 프로세스는 이 때 종료되며 스파크 애플리케이션은 클러스터 내에서 수행된다.
애플리케이션 시작
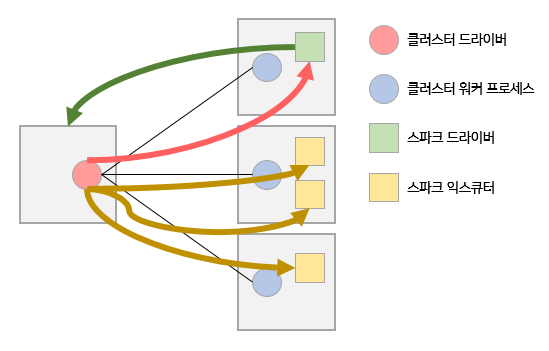
드라이버 프로세스가 실행된 다음 사용자 코드가 실행된다. 사용자 코드에는 반드시 스파크 클러스터를 초기화하는 SparkSession이 포함되어야 한다. SparkSession은 클러스터 매니저와 통신(초록선)하여 스파크 익스큐터 프로세스의 실행(노란선)을 요청한다.
클러스터 매니저가 익스큐터 프로세스를 시작하고 결과를 응답받아 익스큐터의 위치와 정보를 드라이버 프로세스로 전송(붉은선)하는데, 이 작업이 완료되면 스파크 클러스터가 완성된다.
어플리케이션 실행

드라이버와 워커는 코드를 실행하고 데이터를 이동하는 과정에서 서로 통신한다. 드라이버는 워커에게 태스크를 할당하고 태스크를 할당받은 워커는 태스크의 상태와 결과(성공/실패) 여부를 드라이버에 전송한다.
어플리케이션 완료
스파크 어플리케이션의 실행이 완료되면 드라이버 프로세스가 성공이나 실패 중 하나의 상태로 종료된다. 그런 다음 클러스터 매니저는 드라이버가 속한 스파크 클러스터의 모든 익스큐터를 종료시킨다. 이 시점에 클러스터 매니저에 요청해 스파크 어플리케이션의 성공/실패 여부를 확인할 수 있다.
'Data Engineering > Spark' 카테고리의 다른 글
| spark-submit (0) | 2022.02.20 |
|---|---|
| Spark의 핵심 RDD (0) | 2022.02.08 |
| Spark Application Architecture - 실행 모드 (0) | 2022.02.08 |
| Spark Application Component - Component (0) | 2022.02.08 |